

La Data Science è una disciplina “onnivora”, consuma conoscenza da tante altre discipline: matematica e statistica per iniziare, ma anche tanta computer science, senza trascurare la data visualization che assume, sotto certi aspetti, forti tratti percettivi e financo artistici.
Per un principiante entrare nella Data Science significa innanzitutto rivedere le proprie competenze di statistica e di matematica di base. In questo post vediamo quali sono le più importanti e quali competenze invece sono richieste più raramente.
Analisi
L’analisi matematica (“Calculus” in inglese) è una delle tecniche che servono al data scientist per capire e risolvere problemi come: a) calcolare i massimi/minimi delle funzioni b) derivare in maniera corretta le differenze prime/seconde dei dati.
Queste tecniche generali tornano molto utili quando si ha in mente un modello, una funzione che rappresenta i dati e la si vuole confrontare con i dati veri, in gergo si dice “fare il fit” della funzione. Più raramente al data scientist viene chiesto di usare il calcolo integrale e più raramente ancora risolvere equazioni differenziali, tema che è molto più comune a certi settori dell’ingegneria tradizionale.
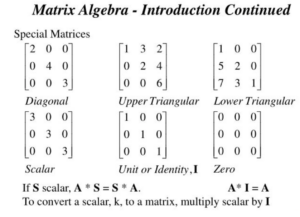
Calcolo matriciale
La forma naturale dei dati per un data scientist è la matrice: la tabella a doppia entrata: righe e colonne. Quando si lavora un file excel o un più pratico CSV è normale infatti lavorare su tabelle, che dal punto di vista matematico sono niente altro che matrici.
Sulle matrici occorre quindi saper fare tutte le trasformazioni di base del calcolo matriciale: prodotti di matrici, determinanti ed autovalori/autovettori tornano utili durante calcoli quali il clustering e sebbene siano i software a fare queste operazioni è necessario avere ben chiara la definizione di autovalore.
Capita poi molto spesso di fare calcoli semplici come la trasposizione di matrici, talvolta la riduzione a matrice triangolare: durante queste operazioni è necessario sapere che i metodi numerici di calcolo matriciale possono andare incontro a problemi di convergenza e che più in generale lavorare su numeri a virgola mobile può – dopo poco tempo – accumulare anche notevoli errori.
Statistica di base
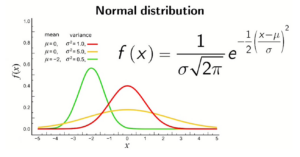
Il data scientist deve sapere tutto, ma proprio tutto, sugli indici di tendenza centrale: media, mediana, e moda devono essere naturali e banali per un data scientist. In particolare deve sempre avere ben chiari i concetti di robustezza, bias e outlier che si legano naturalmente agli indici di dispersione (deviazione media assoluta e deviazione standard).
Il data scientist conosce molto bene le distribuzioni statistiche e per esempio cosa significa trovarsi a 3 sigma rispetto alla media, sicuramente la distribuzione Gaussiana gli è ben nota ma non deve trascurare anche la Poisson (distribuzione per gli eventi rari) e la binomiale. La sua formazione in statistica di base può dirsi completa.
Statistica avanzata
La statistica più avanzata utilizza tantissimo i test per l’inferenza: dalla semplice correlazione (che come è ben noto non è causalità) fino ai test che associano e misurano i risultati dei test di significatività. Deve conoscere come fare “lo zero” ovvero come trovare – con tecniche di randomizzazione – il valore teorico che i dati assumerebbero se fossero perfettamente casuali.
Tutti questi metodi aiutano il data scientist a costruire il livello di significatività che è il metodo scelto dal data scientist per dare forza alle proprie conclusioni: con quale forza si può trarre una conclusione dai dati? Con quale livello di confidenza?
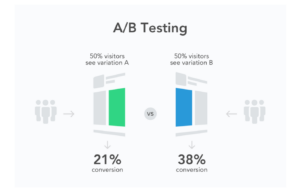
Concludono il bagaglio di statistica avanzata tutti i multitest come il multi arm bandit o gli A/B test che vengono usati in statistica per capire se due o più gruppi hanno caratteristiche differenti tra loro. Gli A/B test sono comunemente utilizzati nel marketing per confrontare i prodotti tra loro.
Computer science
Il data scientist è un buon programmatore che di solito utilizza linguaggi come R o Python, conosce bene l’uso del controllo di versione Git ed il linguaggio SQL. La sua programmazione si avvale dell’orientamento agli oggetti ed ove possibile anche dei test unitari. Talvolta il data scientist utilizza anche i database noSQL come MongoDB o CouchDb o le versioni equivalenti dei vari cloud vendors (AWS, Google, Microsoft).
Per quanto il data scientist non sia specificamente un ingegnere dei dati la sua cultura sul data engineering è sufficientemente vasta.