
Il patriarca Giuseppe è identificato nella Bibbia come “interprete di sogni”, capace di darne spiegazione e di intuire il futuro, grazie ad un dono divino.
In quegli anni, il faraone Ramses faceva un sogno ricorrente: “ho visto sette vacche grasse e belle. Poi ho visto sette vacche magre e ossute. E le vacche magre mangiavano quelle grasse. Nel secondo sogno ho visto sette spighe di grano piene e mature che crescevano su uno stelo. Poi ho visto sette spighe di grano sottili e bruciate. E le spighe di grano sottili inghiottirono le sette spighe di grano buone.”
Il sogno, venne interpretato da Giuseppe, come la rappresentazione di un ciclo naturale che stava a significare: sette anni di abbondanza che venivano seguiti da sette anni di carestia. Giuseppe al tempo suggerì al faraone di accantonare parte del grano prodotto ogni anno, e così facendo salvò l’Egitto da una grave carestia.
In questo sogno, se lo leggiamo con gli occhi della scienza moderna, troviamo due elementi importanti. Il “ciclo” ovvero la periodicità della natura che alterna periodi di eccesso di piovosità, a periodi di siccità e contemporaneamente l’idea che il futuro possa essere in qualche modo predetto a partire dal passato.
I due concetti danno forma allo studio delle serie temporali. La cui disciplina è alla base di quella che in Machine Learning si chiama “predictive analytics”. Il futuro si “predice” a partire da quello che si realizza realizzato e misura nel passato, mentre i cicli sono gli elementi naturali delle serie, magari semplicemente seguono l’alternarsi della ore della giornata, o le stagioni.
Di seguito un esempio di serie temporale ciclica:
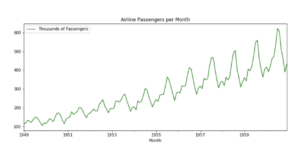
In questo grafico i passeggeri che usano l’aereo sono contati, negli USA, mese per mese in migliaia dal 1949 fino al 1961. Si nota una crescita del traffico, che sale verso tempi più recenti. Ma soprattutto, si notano dei picchi che si ripetono con regolarità: ogni estate la gente si sposta per andare in vacanza e questo picco di viaggiatori inizia a vedersi a partire dalla primavera.
Il ciclo in questo caso è annuale, ogni anno ci sono dei picchi in estate e dei periodi di minore traffico in autunno. I cicli possono anche essere multipli. Il grafico sopra potrebbe avere un picco minore (in questo grafico non visibile) anche nei weekend e quindi il ciclo annuale si sovrappone a quello settimanale.
Guardando il plot si potrebbe essere tentati di proiettare il grafico seguendo la forma degli ultimi anni, e rispettando la scala:
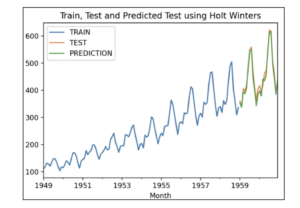
I metodi di “predictive analytics” sono di fatto dei metodi matematici per trovare queste proiezioni geometriche nel futuro.
Facendo comunque molta attenzione a cosa si intende per predizione. Il grafico sopra sembrerebbe fornire dei valori “univoci” per la predizione. Invece nella realtà la predizione ha degli intervalli di confidenza che sono delle bande colorate che implicano un errore nella predizione che tende tra l’altro a crescere con il tempo.
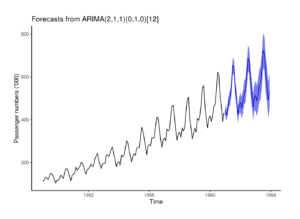
Ecco un esempio ancora più preciso
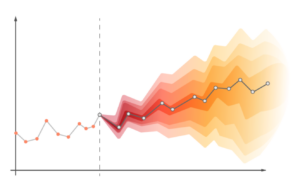
La serie temporale si proietta nel tempo con un errore crescente, rendendo il forecast sempre meno attendibile nel tempo.
La predictive analytics è quella disciplina che prova a determinare i migliori modelli per stabilire i valori futuri aggiungendo però a questi valori un intervallo di confidenza che aumenta con il passare del tempo.
Vedendo ora quali sono i limiti di questi modelli e di questi tentativi di predizione del futuro. La prima cosa è già stata intravista, con il passare del tempo la validità della predizione diminuisce, l’intervallo di confidenza diventa più ampio e l’incertezza aumenta di parecchio.
Tuttavia, il limite maggiore accade quando le serie temporali che si vogliono predire non hanno un carattere periodico e di trend, ma appaiono dominate dalla casualità e dal rumore.
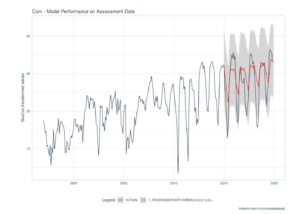
In questo caso la serie temporale è molto mobile, con dei picchi che non sono affatto regolari e spesso anche molto profondi, la predizione in colore rosso è molto meno capace di catturare la reale variabilità (in nero) e le bande di confidenza appaiono molto estese.
In questo caso la presenza di una forte variabilità e la mancanza di un ciclo evidente, forza i modelli di predizione ad essere conservativi, predicendo solo quei valori che appaiono “nella media”.
Questo fenomeno è particolarmente nefasto nella cosiddetta “demand forecasting”, predizione della domanda. Guardando per esempio i valori in rosso dal 2015 in poi, durante i picchi il valore reale può discostarsi anche del 200% un valore “normale” in demand forecasting che ha un impatto enorme nella produzione di beni materiali.
Supponendo che la domanda di beni segua la linea nera, mentre la produzione quella rossa. Avere il picco negativo della domanda che vale la metà (circa anno 2018) di quello del 2020, significa che la produzione è doppia rispetto alla domanda, con un crollo probabile dei prezzi ed un forte invenduto. Mentre qualche mese dopo la ripresa della domanda renderà il sistema incapace di soddisfare la richiesta (anche se in misura minore).
In altre parole la predizione funziona “in media” trovando cicli e periodi successivi con un errore che sale e scende rispetto alla curva reale, ma l’errore sul singolo punto può essere molto grande anche del 200% e condizionare fortemente cose come la produzione e la capacità di soddisfare la domanda.
In conclusione la predictive analytics è in grado di fare previsioni nel futuro e in media funziona molto bene, degradando per qualità con il passare del tempo. Contemporaneamente non è sempre in grado – specie in mancanza di cicli e regolarità evidenti – di predire correttamente i singoli punti, portando anche ad errori molto grandi.
Questo paradosso dell’ottima predizione in media, ma della pessima predizione puntuale è una caratteristica saliente della predictive analytics e dovrebbe invitare alla prudenza in settori come la previsione della domanda. Come sempre gli strumenti matematici sono importanti, ma la loro applicazione dipende fortemente dalla maturità di chi lo sperimenta e del Data Scientist.